analyze.py
extract.py
Webstemmer uses the following assumptions for analyzing web pages:
Webstemmer tries to identify a page layout by finding invariant features that are preserved across different pages. Then it tries to remove unchanged parts (which are mostly banners and navigation links) within the same page layout.
There are two techniques that are extensively used in this algorithm. One is called edit distance (levenshtein distance). This is used to calculate the similarity between two distinct strings. The other technique is clustering, which is to group similar objects based on their distance defined by an arbitrary metric. They have been developed since 1960s.
Layout analysis is to extract a "pattern" of HTML pages by
clustering pages which have similar structures (layouts) to each
other. To perform clustering, one has to compare multiple HTML
pages and compute its similarity by comparing the features of each
page. Group the pages which is similar to each other and extract
common features as the pattern of the group (cluster). Here is the basic
algorithm to do this in analyze.py program.
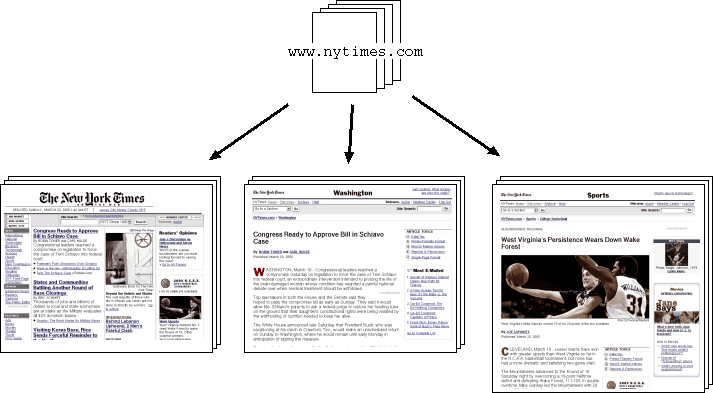
First analyze.py decomposes each HTML page into a
sequence of "layout blocks" (Fig. 1). Though HTML elements normally forms a
tree structure, we only take HTML block elements such as
<p>, <div>, and
<h1> and <title> element.
We interpret an HTML page as a sequence of layout blocks. Layout
blocks are used as features to compute the similarity of different
pages. Here is an example of a HTML page and its layout blocks:
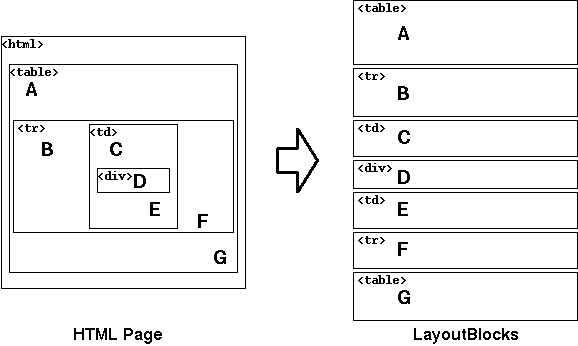
Fig. 1. Extracting a sequence of layout blocks from HTML.
The similarity between two pages is determined by the edit distance of the layout block sequences. This is similar to comparing two strings (i.e. diff). First obtain the maximum common sequence (MCS) of layout blocks and compute the ratio of common layout blocks (Fig. 2) between two sequences A and B, as in:
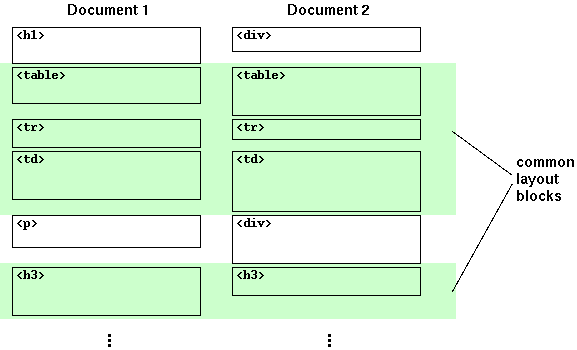
Fig. 2. Comparing layout block sequences.
To perform clustering, one need to compute the similarity scores
for all possible combinations of N pages, namely
N x N pairs. The algorithm used in the
analyze.py program tries to reduce the number of
combinations, so the actual number of similarities might be less
than N x N. A pages whose similarity exceeds a
certain threshold is grouped into the same cluster. The clustering
is performed in a hierarchical manner. This threshold is given by
'-t' option in the analayze.py program.
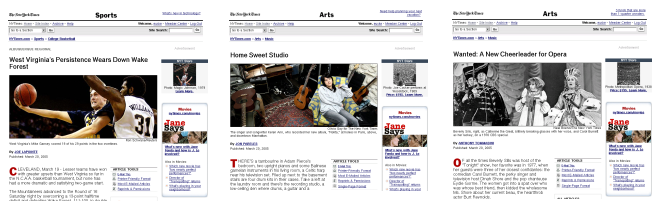
After obtaining clusters, extract the common layout blocks
contained in all the pages in a group (cluster) (Fig. 3). These layout
blocks form a "layout pattern" which is the output of this
program.
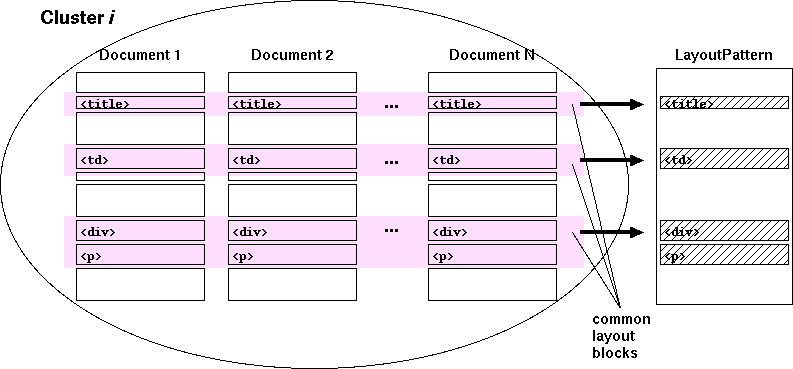
Fig. 3. Generating a layout pattern.
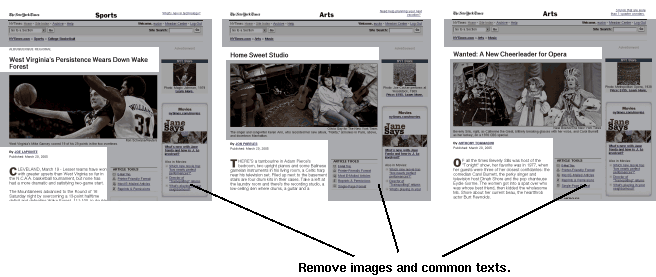
The next step is to find banners and/or navigation links from each layout pattern. Each layout block is given a value called "DiffScore", which indicates how much the texts in a block varies to each other:
-T' option in extract.py
program.
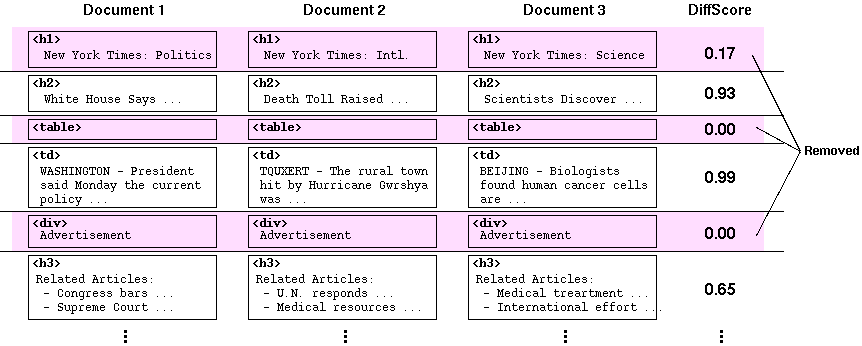
Fig. 4. Finding the common texts between different pages.
After filtering out static texts, we try to discover a layout
block which is the page title. The title block is determined by
comparing the text contained in that block and one of anchor texts
(a string surrounded by a link tag <a>
... </a>) which refer to that page. In most of the
news sites, it is known that the anchor text of a link to an
article represents the title of that article. So compute the
similarity between texts from each layout block and the anchor
texts, and choose the block which has the hightest similarity
(Arrow 1. in Fig. 5). This is also based on the edit distance of
strings. The title block is determined in the clustering process
(i.e. analyze.py), whereas the range of main texts
can be adjusted dynamically in the text extraction.
There is an alternative way to find a title block. When there is
no anchor text available for that page, we consider the layout
block that is most similar to one of the main text and appears
before that text block, as a title (Arrow 2. in Fig. 5). This was
the only way of finding a title in the previous versions of
Webstemmer. But this is a "fallback" method now, because the
accuracy of title detection is not as good as the first
method. The threshold of the similarity between title and main
text is given by '-T' option in
analyze.py.
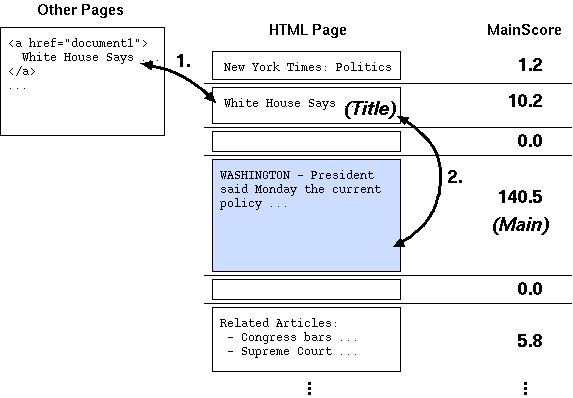
Fig. 5. Discovering the title and main text from the page.
In order to find the main text of each page, we compute the "MainScore" for each layout block, which shows how much significant text is included within that block:
-M' option in extract.py program.
The sequence of layout blocks in each cluster is stored in a layout pattern file. Each layout block in a cluster has a DiffScore and MainScore. Then, each cluster can have the score of significence, indicating how much that cluster is important. This is based on the number of significant characters (excluding anchor texts) in the main text and the number of pages in the cluster:
The detail of the patter file format is described in Anatomy of Pattern Files.
The
You can add an extra restriction by using "strict mode"
(
After determining the page layout pattern, the program extracts
texts from the layout blocks selected by the user-specified
thresholds, and output them as either
The following sample pattern was obtained from cnn.com.
(For reader's convenience, a pattern is split into multiple lines,
which is not allowed in an actual pattern file.)
Well, in most web pages texts might be extracted in a much easier way,
like picking up lines with a certain number of words or
punctuations... So the attempt explained within this page is
basically nonsense. However, it just looks cool.
Last Modified: Thu Sep 6 12:58:13 JST 2007
Extracting Texts - extract.py
extract.py program takes a layout pattern file
generated by analyze.py and extract the main text and
its title from HTML pages. First it decomposes each HTML page into
layout blocks in the same way as the analyzer. Then it tries to
find the most similar sequence of layout blocks from the pattern
file (Fig. 6). If the similarity exceeds a certain threshold (given by
'-t' option), it is considered that the page has
the same layout pattern as the one in the pattern file.
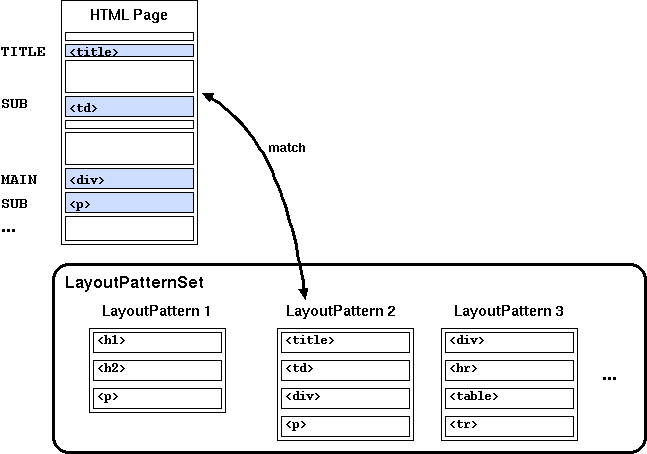
Fig 6. Searching a layout pattern which matches the given page.
-S option) which prevents incomplete matching. In
the strict mode, the program rejects a layout pattern if any of
its layout block is missing in the page, no matter how many layout
blocks are overlapping. This allows you to identify page layout
improved accuracy. However, in some newspapers (such as several
U.S. newspapers, which use slightly different layouts on each
day,) you might get lower recall, which means the number of
matching pages might be decreased.
TITLE:,
MAIN: or SUB: according to its
DiffScore and MainScore value.
Anatomy of Pattern Files
analyze.py outputs patterns as a text file. It has
one layout pattern per line. Each pattern contains several values
formatted by Python's repr() function. An empty line
and a line which begins with a '#' is regarded as a
comment. Each pattern follows a couple of comment lines which shows
the score of the pattern (indicating how likely the page is an article)
and original page IDs that belong to that pattern when learning.
### version=0.6.0 (Webstemmer Version)
### fname='cnn.200511210103.zip' (Source file used for learning)
### cluster_threshold=0.970000 (Clustering threshold of page similarity)
### title_threshold=0.600000 (Threshold for detecting a title)
### pages=74 (Total number of pages used for learning)
# 3759.96885103 <200511210103/www.cnn.com/2005/EDUCATION/11/18/principal.shaming.ap/index.html> (pattern 1)
# (Pages which belong to this cluster)
# 200511210103/www.cnn.com/2005/EDUCATION/11/18/principal.shaming.ap/index.html
# 200511210103/www.cnn.com/2005/WORLD/meast/11/20/iran.nuclear.ap/index.html
# 200511210103/www.cnn.com/2005/EDUCATION/11/18/student.progress.ap/index.html
# 200511210103/www.cnn.com/2005/TRAVEL/DESTINATIONS/11/18/homer.exhibit.ap/index.html
# 200511210103/www.cnn.com/2005/US/11/20/lost.in.morgue.ap/index.html
(3759.9688510285455, (Overall score of the cluster)
'200511210103/www.cnn.com/2005/EDUCATION/11/18/principal.shaming.ap/index.html', (Cluster ID)
9, (Index of the title layout block in the sequence)
[ (List of layout blocks)
# (diffscore, mainscore, block feature)
(0.54130434782608694, 24.899999999999999, 'title'),
(0.0, 0.0, 'table:align=right/tr:valign=middle/td:class=cnnceilb'),
(0.0, 0.0, 'table:id=cnnceil/tr/td:class=cnnceilw'),
(0.052631578947368418, 0.0, 'ul:id=nav/li/div'),
(0.0, 0.0, 'ul:id=nav/li:class=money/div'),
(0.0,0.0, 'ul:id=nav/li:class=sports/div'),
(0.047314578005115092, 0.0, 'ul:id=nav/li/div'),
(0.0, 0.0, 'ul:id=nav/li:class=autos/div'),
(0.0, 0.0, 'td:id=cnnnavbar:rowspan=2/div:class=cnnnavbot/div'),
(0.76451612903225807, 23.699999999999999, 'tr:valign=top/td:id=cnnarticlecontent/h1'),
(0.085365853658536592, 1.3999999999999999, 'div:class=cnninteractiveelementscontainer/div:class=cnnieheader/h3'),
(0.73124999999999996, 23.399999999999999, 'div:class=cnniebox/div:class=cnnieboxcontent/div:class=cnnemailalertoptionrow'),
(0.0, 0.0, 'div:class=cnniebox/div:class=cnnieboxcontent/div:class=cnnalertsbuttonrow'),
(0.0, 0.0, 'div:class=cnninteractiveelementscontainer/div:class=cnniebox/div:class=cnnieboxcontent cnnalertsfooterrow'),
(0.99176016830294533, 2262.8000000000002, 'tr:valign=top/td:id=cnnarticlecontent/p'),
(0.0, 0.0, 'td:id=cnnarticlecontent/div:class=cnnstorycontrib/p'),
(0.0, 0.0, 'tr:valign=top/td/div:class=cnnstorytools'),
(0.0, 0.0, 'table:id=cnnstorytoolstimebox/tr/td'),
(0.37226277372262773, 0.0, 'tr:valign=top/td/div:class=cnnbinnav'),
(0.7265625, 0.0, 'table:class=cnnstoryrelatedstopstory/tr/td'),
(0.66804979253112029, 0.0, 'td/div:class=cnnstorybinsublk/div'),
(0.0, 0.0, 'tr:valign=top/td/div:class=cnnbinnav'),
(0.0, 0.0, 'table:class=cnnstoryrelatedstopstory/tr/td'),
(0.0, 0.0, 'td/div:class=cnnstorybinsublk/div'),
(0.0, 0.0, 'tr/td/div:class=cnn4pxlpad'),
(0.0, 0.0, 'table/tr/td'),
(0.0, 0.0, 'table/tr/td:align=right:class=cnn7pxrpad'),
(0.0, 0.0, 'table:id=cnnfoot/tr:valign=top/td'),
(0.0, 0.0, 'table/tr/td:valign=top'),
(0.0, 0.0, 'table/tr:class=cnnnopad/td')
]
)
Conclusion