Ωό 1. ΚΤΒΔΛρΜ»ΛΟΛΩΞ–ΓΦΞΗΞγΞσ
≥ΒΆΉ: ΛΔΛκΦοΛΈΧδ¬ξΛœΓΔΚΤΒΔΛρΜ»ΛΠΛ»»σΨοΛΥΗζΈ®≈ΣΛΥΒ≠Ϋ“Λ«Λ≠ΛκΓΘ ΛΖΛΪΛΖ¬γΈΧΛΈΞ«ΓΦΞΩΛράΗά°ΛΙΛκΛηΛΠΛ ΚΤΒΔ≈ΣΦξ¬≥Λ≠ΛœΗΖΧ©ΛΥά©ΗφΛΙΛκ…§ΆΉΛ§ΛΔΛξΓΔ ΛΫΛΠΛΛΛΟΛΩΞΉΞμΞΑΞιΞΏΞσΞΑΛœΤώΛΖΛΛΓΘPython 2.2 Α ΙΏΛΪΛιΜ»Ά―≤Ρ«ΫΛΥΛ ΛΟΛΩ ΞΗΞßΞΆΞλΓΦΞΩΛρΜ»ΛΠΛ»ΓΔ¥ ΖιΛ Ξ≥ΓΦΞ…ΛρΑίΜΐΛΖΛΡΛΡΓΔ Λ≥ΛΠΛΖΛΩΦξ¬≥Λ≠ΛρΛΪΛσΛΩΛσΛΥά©ΗφΛΙΛκΛ≥Λ»Λ§Λ«Λ≠ΛκΓΘ
Λ≥ΛΈ ΗΫώΛ«Μ»ΛοΛλΛΤΛΛΛκΞΫΓΦΞΙΞ≥ΓΦΞ…Λœ Λ≥ΛΝΛιΓΘ ΞΉΞλΞΛΞσΞΤΞ≠ΞΙΞ»»«Λœ Λ≥ΛΝΛιΓΘ
ΚΤΒΔΛœ»σΨοΛΥΕ·ΈœΛ ΞαΞΪΞΥΞΚΞύΛ«ΛΙΓΘ ΜΰΛΥΛ≥ΛλΛœΚ°ΆπΛρΨΖΛ·Λ≥Λ»ΛβΛΔΛξΛόΛΙΛ§ΓΔΛ’ΛΡΛΠΚΤΒΔΛρΜ»ΛΠΛ»ΓΔΧδ¬ξΛρ¥ Ο±ΛΥΒ≠Ϋ“ΛΙΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙΓΘ ΛΔΛκΦξ¬≥Λ≠Λ§ΑΖΛΠΞ«ΓΦΞΩΈΧΛ§ΜΊΩτ≈ΣΛΥΝΐΛ®ΛκΛηΛΠΛ ΨλΙγΓΔΛ≥ΛλΛœΛ»Λ·ΛΥΛΔΛΤΛœΛόΛξΛόΛΙΓΘ ΧΎΙΫ¬ΛΛΈΟΒΚςΛ§ΛΛΛΛΈψΛ«ΛΖΛγΛΠΓΘΧΎΛΈ≥Τάα≈άΛœΛ“Λ»ΛΡΑ ΨεΛΈΜ“ΛρΜΐΛΟΛΤΛΛΛόΛΙΛ§ΓΔ ≤ΦΛΊ≤ΦΛΊΛ»ΛΩΛ…ΛΟΛΤΛΛΛ·ΛΥΛΡΛλΛΤΓΔάα≈άΛΈΩτΛœΜΊΩτ≈ΣΛΥΝΐΛ®ΛΤΛΛΛ≠ΛόΛΙΓΘ Λ«ΛβΓΔΛβΛΖΛΙΛΌΛΤΛΈάα≈άΛ§ΑλΆΆΛΥΤ±ΛΗΦοΈύΛΈΛβΛΈΛ«ΛΔΛλΛ–ΓΔΛόΛΟΛΩΛ·Τ±ΛΗΦξ¬≥Λ≠Λ§ ΛΙΛΌΛΤΛΈάα≈άΛΥ¬–ΛΖΛΤΛ·ΛξΛΪΛ®ΛΖ≈§Ά―Λ«Λ≠ΛόΛΙΓΘ
Λ«ΛβΧΎΛΈΟΒΚςΛœΛΣΛΫΛιΛ·ΛέΛ…ΛσΛ…ΛΈΖΉΜΜΒΓ≤ ≥ΊΛΈΕΒ≤ ΫώΛ« άβΧάΛΒΛλΛΤΛΛΛκΛΈΛ«ΓΔΛΔΛόΛξΛΣΛβΛΖΛμΛ·ΛœΛΔΛξΛόΛΜΛσΓΘ Ο·Λ«ΛβΧΎΛρΟΒΚςΛΙΛκΛ»Λ≠ΛΥΛœΓΔΛέΛ»ΛσΛ…≤ΩΛβΙΆΛ®ΛΚΛΥΚΤΒΔΛρΜ»ΛΠΛ≥Λ»Λ«ΛΖΛγΛΠΓΘ ΛΖΛΪΛΖΓΔΛβΛΝΛμΛσΚΤΒΔΛ§ΧρΛΥΈ©ΛΡΛηΛΠΛ ΈψΛœΛέΛΪΛΥΛβ¬τΜ≥ΛΔΛξΛόΛΙΓΘ ΛΫΛ≥Λ«Λ≥Λ≥Λ«Λœ ΧΛΈΈψΛρΗΪΛΤΛΏΛόΛΖΛγΛΠΓΘ
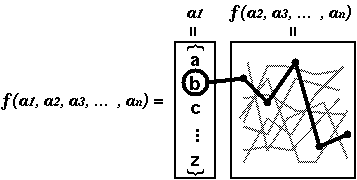
Α ≤ΦΛΈΛηΛΠΛ ¥ΊΩτ f ΛρΙΆΛ®ΛόΛΙΓΘ Λ≥ΛλΛœΞΌΞ·Ξ»ΞκΛΈΫΗΙγ (V1, V2, V3, ... , Vn) ΛρΑζΩτΛ»ΛΖΛΤΛ»ΛξΓΔ Vi ΛΈ≥ΤΆΉΝ«Λ§Λ»ΛξΛΠΛκΝ»ΛΏΙγΛοΛΜΛΙΛΌΛΤΛΪΛιΛ ΛκΫΗΙγΛρ ÷ΛΙΛβΛΈΛ»ΛΖΛόΛΙΓΘΛΣΛΈΛΣΛΈΛΈΝ»ΛΏΙγΛοΛΜΛœΓΔnΆΉΝ«ΛΈΞΌΞ·Ξ»Ξκ (xi1, xi2, ... , xim) ΛΪΛιΛ ΛξΛόΛΙΓΘΛ≥Λ≥Λ« xij Λœ Vi ΛΈΆΉΝ«Λ«ΛΙΓΘΛ≥ΛΈ¥ΊΩτΛ§ ÷ΛΙΞΌΞ·Ξ»ΞκΛœΛΦΛσΛ÷Λ« |V1| x |V2| x |V3| x ... x |Vn| ΗΡΛΔΛκΛ≥Λ»ΛΥΛ ΛξΛόΛΙΓΘ
Λ≥ΛΈ¥ΊΩτΛρ Python Λ«Φ¬ΝθΛΙΛκΛ≥Λ»ΛρΙΆΛ®ΛΤΛΏΛόΛΖΛγΛΠΓΘ Ο±ΫψΛΒΛΈΛΩΛαΓΔΛ≥Λ≥Λ«ΛœΞΌΞ·Ξ»Ξκ Vi ΛΈΛΣΛΈΛΣΛΈΛρ …ΫΛΙΛΈΛΥ ΗΜζΈσΞΣΞ÷ΞΗΞßΞ·Ξ»ΛρΆ―ΛΛΛκΛ≥Λ»ΛΥΛΖΛόΛΙΓΘ Λ≥ΛΈ¥ΊΩτΛœΞΌΞ·Ξ»ΞκΛΈΫΗΙγΛρΞξΞΙΞ»Λ»ΛΖΛΤ ÷ΛΙΛ≥Λ»ΛΥΛΖΛόΛΖΛγΛΠΓΘ ΛΙΛκΛ»ΓΔΆΫΝέΛΒΛλΛκΖκ≤ΧΛœΑ ≤ΦΛΈΛηΛΠΛΥΛ ΛξΛόΛΙ:
f([]) --> [''] # 1
f(['abc']) --> ['a', 'b', 'c'] # 3
f(['abc', 'xyz']) --> ['ax', 'ay', 'az', 'bx', 'by', 'bz', 'cx', 'cy', 'cz'] # 9
f(['abc', 'xyz', '123']) --> ['ax1', 'ax2', 'ax3', 'ay1', 'ay2', 'ay3', 'az1', 'az2', 'az3',
'bx1', 'bx2', 'bx3', 'by1', 'by2', 'by3', 'bz1', 'bz2', 'bz3',
'cx1', 'cx2', 'cx3', 'cy1', 'cy2', 'cy3', 'cz1', 'cz2', 'cz3'] # 27
ΑλΗΪΛΙΛκΛ»ΓΔΛ≥ΛλΛœ¥ Ο±ΛΥΦ¬ΝθΛ«Λ≠ΛΫΛΠΛΥΜΉΛ®ΛκΛΪΛβΛΖΛλΛόΛΜΛσΓΘ ΛβΛΖΛΪΛΙΛκΛ»ΚΤΒΔΛρΜ»ΛοΛ Λ·ΛΤΛβ¥ Ο±ΛΥΫώΛ±ΛΫΛΠΛΥΗΪΛ®ΛκΛΈΛ«ΛœΛ ΛΛΛ«ΛΖΛγΛΠΛΪΓΘ Λ«ΛœΛδΛΟΛΤΛΏΛόΛΖΛγΛΠΓΘ
Κ«ΫιΛΥΓΔΛβΛΖΚΤΒΔΛρΛόΛΟΛΩΛ·Μ»ΛοΛ ΛΛΛ»ΛΙΛκΛ»ΓΔ ΞΉΞμΞΑΞιΞύΛœΛΣΛΫΛιΛ·Λ≥ΛσΛ ¥ΕΛΗΛΈΛβΛΈΛΥΛ ΛκΛ»ΜΉΛΛΛόΛΙ:
def f0(args): counter = [ 0 for i in args ] r = [] while 1: r.append("".join([ arg1[i] for arg1,i in zip(args, counter) ])) carry = 1 x = range(len(args)) x.reverse() # x == [len(args)-1, len(args)-2, ..., 1, 0] for i in x: counter[i] += 1 if counter[i] < len(args[i]): carry = 0 break # "for" ΛΪΛ黥˱Λκ counter[i] = 0 else: break # "while" ΛΪΛ黥˱Λκ return r
ΚΤΒΔΛρΜ»ΛοΛ ΛΛΨλΙγΓΔΞΉΞμΞΑΞιΞύΛœΛΙΛΌΛΤΛΈΝ»ΛΏΙγΛοΛΜΛράΗά°ΛΙΛκΛΩΛαΛΥ
≈”ΟφΛΈΨθ¬÷Λρ≤ΩΛιΛΪΛΈ ΐΥΓΛ«ΛΙΛΌΛΤΒ≠≤±ΛΖΛΤΛΣΛΪΛΆΛ–Λ ΛξΛόΛΜΛσΓΘ
Λ≥ΛΈΞΉΞμΞΑΞιΞύΛ«ΛœΓΔΝ¥≤ΟΜΜ¥ο (full-adder) ΛΈΛηΛΠΛ ΛβΛΈΛρήοΞεΞλΓΦΞ»ΛΖΛόΛΖΛΩΓΘ
ΛόΛΚΞΉΞμΞΑΞιΞύΛœάΑΩτΛΈΞξΞΙΞ»ΛρΫύ»ςΛΖΛόΛΙΓΘΛΫΛΖΛΤΛ≥ΛΈΚ«≤ΦΑΧΛΈΖεΛΥ 1 Λρ≤ΟΛ®ΛηΛΠΛ»ΛΖΛόΛΙΓΘ
ΞκΓΦΞΉΛ§ΛόΛοΛκΛΩΛ”ΛΥΓΔΛ≥ΛΈ¥ΊΩτΛœΑζΩτΛΥ≈œΛΒΛλΛΩΆΉΝ«ΛρΖκΙγΛΖΛΤ ―Ωτ
r ΛΥΤΰΛλΛΤΛΛΛ≠ΛόΛΙΓΘΛΖΛΪΛΖΛ≥ΛΈΞΉΞμΞΑΞιΞύΛΈΛ’ΛκΛόΛΛΛœΓΔ
"carry" Λ Λ…ΛΈΑ’ΧΘΩΦΡΙΛ ―ΩτΧΨΛ§Ξ“ΞσΞ»ΛΥΛœΛ ΛκΛβΛΈΛΈΓΔ
Ν¥¬ΈΛ»ΛΖΛΤΛœΛοΛΪΛξΛΥΛ·ΛΛΛβΛΈΛ«ΛΙΓΘ
Λ«ΛœΚΤΒΔΛρΜ»ΛΠΛ»Λ…ΛΠΛ ΛκΛ«ΛΖΛγΛΠΛΪΓΘ¥ΊΩτ f ΛœΦΓΛΈΛηΛΠΛΥΚΤΒΔ≈ΣΛΥΡξΒΝΛ«Λ≠ΛόΛΙ:
| f(Vi, Vi+1, ... , Vn) = | ({xi1} + f(Vi+1, ... , Vn)) + |
| ({xi2} + f(Vi+1, ... , Vn)) + | |
| ... | |
| ({xim} + f(Vi+1, ... , Vn)) . |
Λ≥ΛΈΡξΒΝΛρΜ»ΛΟΛΤΦΪ §ΦΪΩ»ΛρΗΤΛ”Ϋ–ΛΙΛηΛΠΛΥΛΙΛκΛ»ΓΔΞΉΞμΞΑΞιΞύΛœΛΚΛΟΛ»¥ Ο±ΛΥΛ ΛξΛόΛΙ:
def fr(args): if not args: return [""] r = [] for i in args[0]: for tmp in fr(args[1:]): r.append(i + tmp) return r
Λ≥ΛλΛœ»σΨοΛΥΡΨάή≈ΣΛΥΦ¬ΝθΛΖΛΩΛβΛΈΛ«ΛΙΓΘ ΚΤΒΔΛΈ ΊΆχΛ Λ»Λ≥ΛμΛœΓΔΛΔΛκΧδ¬ξΛρΛΛΛ·ΛΡΛΪΛΈΓ÷ΞΒΞ÷Χδ¬ξΓΉΛΥ §≥δΛΖΓΔΛΫΛλΛιΛΈ≥ΤΞΒΞ÷Χδ¬ξΛΥΛβΛόΛΟΛΩΛ·Τ±ΛΗΦξ¬≥Λ≠Λ§Μ»Λ®ΛκΛ≥Λ»Λ«ΛΙΓΘ Λ≥ΛΈΞΉΞμΞΑΞιΞύΛ«ΛœΟ±ΛΥ≥ΤΑζΩτΛΈΚ«ΫιΛΈΆΉΝ«ΛρΛ»ΛΟΛΤΛ≠ΛΤΓΔ ΛΫΛλΛρΛ≥ΛΈ¥ΊΩτΦΪΩ»ΛρΛ“Λ»ΛΡΨ·Λ ΛΛΑζΩτΛ«ΗΤΛ”ΛάΛΖΛΩΛ»Λ≠ΛΈ ΛΙΛΌΛΤΛΈ ÷ΛξΟΆΛΥΡ…≤ΟΛΖΛΤΛΛΛόΛΙ (Ωό 1)ΓΘ
Λ≥ΛλΛόΛ«ΗΪΛΤΛ≠ΛΩ¥ΊΩτΛœΓΔ≈ζΛ®ΛρΛΛΛΟΛΎΛσΛΥ ÷ΛΙΛηΛΠΛ ΛβΛΈΛ«ΛΖΛΩΓΘ ΛΖΛΪΛΖΟΒΚςΛδΩτΛ®ΨεΛ≤Λ Λ…ΛΈΞΔΞΉΞξΞ±ΓΦΞΖΞγΞσΛΥΛηΛΟΛΤΛœΓΔ Λ≥ΛλΛιΛΙΛΌΛΤΛΈΝ»ΛΏΙγΛοΛΜΛρ≥–Λ®ΛΤΛΣΛ·…§ΆΉΛ§Λ ΛΛΨλΙγΛβΛΔΛξΛόΛΙΓΘ ΛδΛξΛΩΛΛΛΈΛœΓΔΛΣΛΈΛΣΛΈΛΈΝ»ΛΏΙγΛοΛΜΛρΛΩΛάΗΓΚΚΛΖΛΤΓΔ Ά―Λ§Κ―ΛσΛάΛιΛΫΛλΛιΛœΦΈΛΤΛκΛηΛΠΛΥΛΖΛΩΛΛΛΈΛ«ΛΙΓΘ
Ϋ–ΈœΛΈΩτΛ§Ψ·Λ ΛΛΛ»Λ≠ΛΥΛœΓΔΛ≥ΛλΛœ¬γΛΖΛΩΧδ¬ξΛ«ΛœΛΔΛξΛόΛΜΛσΓΘ Λ«ΛβΚΤΒΔ≈ΣΦξ¬≥Λ≠Λ«¥ϋ¬‘Λ«Λ≠ΛκΛΈΛœΓΔΛΫΛΈΖκ≤ΧΛ§ΜΊΩτ≈ΣΛΥΝΐΛ®ΛκΛηΛΠΛ ΨλΙγΛ«ΛΖΛΩΓΘ Λ»Λ≥ΛμΛ§»ιΤυΛ Λ≥Λ»ΛΥΓΔΛΫΛΈΛηΛΠΛ ¥ΊΩτΛœΛ’ΛΡΛΠΛΪΛ Λξ¬γΈΧΛΈΫ–ΈœΛράΗά°ΛΖΛόΛΙΓΘ Λ≥ΛλΛœΧδ¬ξΛ«ΛΙΓΘ¬ΩΛ·ΛΈΗάΗλΦ¬ΝθΛ«ΛœΓΔΛ≥ΛλΛιΛΈΫ–ΈœΛΙΛΌΛΤΛρΒ≠≤±ΛΙΛκΛ≥Λ»Λœ Λ«Λ≠ΛόΛΜΛσΓΘΛΣΛΫΛΪΛλΛœΛδΛΪΛλΓΔΒ≠≤±ΆΤΈΧΛΈΗ¬≥ΠΛΥ≈ΰΟΘΛΖΛΤΛΖΛόΛΠΛ≥Λ»Λ«ΛΖΛγΛΠ:
$ ulimit -v 5000 $ python ... >>> for x in fr(["abcdefghij","abcdefghij","abcdefghij","abcdefghij","abcdefghij"]): ... print x ... Traceback (most recent call last): File "<stdin>", line 1, in ? File "<stdin>", line 7, in fr MemoryError
Λ≥ΛλΛΥ¬–ΛΙΛκ≈ΒΖΩ≈ΣΛ ≤ρΥΓΛœΓΔΛ≥ΛλΛιΛρΛΙΛΌΛΤΑέΛ ΛκΨθ¬÷ΛΥάΎΛξΛοΛ±ΛκΛ≥Λ»Λ«ΛΙΓΘ Python Λ«ΛœΓΔΛ≥ΛλΛœΞΛΞΤΞλΓΦΞΩΛρΜ»ΛΟΛΤΙ‘ΛΛΛόΛΙΓΘ
Python Λ«Λœ __iter__ ΞαΞΫΞΟΞ…ΛρΛβΛΡΞ·ΞιΞΙΛœ
ΞΛΞΤΞλΓΦΞΩΛ»ΛΖΛΤΜ»ΛΠΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙΓΘΞΛΞΤΞλΓΦΞΩΛœΒΓ«Ϋ≈ΣΛΥΞξΞΙΞ»Λ»
ΛόΛΟΛΩΛ·Τ±ΛΗΛ«ΛœΛ ΛΛΛβΛΈΛΈΓΔΛΛΛ·ΛΡΛΪΛΈ¥ΊΩτΛΔΛκΛΛΛœ ΗΛ«Λœ
ΞΛΞΤΞλΓΦΞΩΛρΞξΞΙΞ»ΛΈΛΪΛοΛξΛΥΦηΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙ (for, map,
filter Λ Λ…)ΓΘ
class fi: def __init__(self, args): self.args = args self.counter = [ 0 for i in args ] self.carry = 0 return def __iter__(self): return self def next(self): if self.carry: raise StopIteration r = "".join([ arg1[i] for arg1,i in zip(self.args, self.counter) ]) self.carry = 1 x = range(len(self.args)) x.reverse() # x == [len(args)-1, len(args)-2, ..., 1, 0] for i in x: self.counter[i] += 1 if self.counter[i] < len(self.args[i]): self.carry = 0 break self.counter[i] = 0 return r # display def display(x): for i in x: print i, print return
Λ≥ΛΈΞΉΞμΞΑΞιΞύΛ«ΛœΓΔΞ·ΞιΞΙ fi ΛΈΞ≥ΞσΞΙΞ»ΞιΞ·ΞΩΛœ
ΚΤΒΔΞ–ΓΦΞΗΞγΞσΛΈ¥ΊΩτ fr Λ»Τ±ΆΆΛΥΑ ≤ΦΛΈΛηΛΠΛΥΛΖΛΤΜ»ΛΠΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙ:
>>> display(fi(["abc","def"]))
Λ≥ΛΈΞΛΞσΞΙΞΩΞσΞΙΛ§ for ΗΛΥ≈œΛΒΛλΛκΛ»ΓΔ
__iter__ ΞαΞΫΞΟΞ…Λ§ΗΤΛ–ΛλΓΔΛΫΛΈ ÷ΛξΟΆ (Λ≥Λ≥Λ«ΛœΛΫΛΈΞΛΞσΞΙΞΩΞσΞΙΦΪΩ») Λ§
ΞκΓΦΞΉΛΈΞΛΞΤΞλΓΦΞΩΛ»ΛΖΛΤΜ»ΛοΛλΛόΛΙΓΘΥη≤σΞκΓΦΞΉΛρΛόΛοΛκΛΩΛ”ΛΥΞΛΞΤΞλΓΦΞΩΛΈ
next ΞαΞΫΞΟΞ…Λ§ΑζΩτΛ ΛΖΛ«ΗΤΛ–ΛλΓΔΛΫΛΈ ÷ΛξΟΆΛ§ΞκΓΦΞΉ ―ΩτΛΥ≥ «ΦΛΒΛλΛόΛΙΓΘ
ΛΖΛΪΛΖΓΔΛ≥ΛΈΞΉΞμΞΑΞιΞύΛρΆΐ≤ρΛΙΛκΛΈΛœΛΫΛΠΛδΛΒΛΖΛ·ΛœΛΔΛξΛόΛΜΛσΓΘ
ΞΔΞκΞ¥ΞξΞΚΞύ≈ΣΛΥΛœΓΔΛ≥ΛλΛœάηΛΥΛΔΛ≤ΛΩΚΤΒΔΛρΜ»ΛοΛ ΛΛΞ–ΓΦΞΗΞγΞσΛ»
ΜςΛΤΛΛΛόΛΙΓΘnext Λ§ΗΤΛ–ΛλΛκΛΩΛ”ΛΥΓΔΛ≥ΛλΛœ ―Ωτ
counter ΛΥ≥ «ΦΛΒΛλΛΤΛΛΛκΗΫΚΏΛΈΨθ¬÷ΛρΙΙΩΖΛΖΓΔ
ΛΫΛΈΨθ¬÷ΛΥ±ΰΛΗΛΩΖκ≤ΧΛρΛ“Λ»ΛΡ ÷ΛΖΛόΛΙΓΘΛ«ΛβΛ≥ΛλΛœΛΒΛιΛΥ
Λ≥ΛΏΤΰΛΟΛΤΛΛΛκΛηΛΠΛΥΗΪΛ®ΛκΛ«ΛΖΛγΛΠΓΘΛ ΛΦΛ ΛιΛ≥ΛΈΞαΞΫΞΟΞ…Λœ
ΞκΓΦΞΉΛΈΟφΛ«ΗΤΛ–ΛλΛκΛηΛΠΛΥΛ«Λ≠ΛΤΛΛΛόΛΙΛ§ΓΔΛΫΛΈΞκΓΦΞΉΦΪ¬ΈΛœ
Λ≥Λ≥ΛΥΛœΧάΦ®≈ΣΛΥΗΫΛλΛ ΛΛΛΪΛιΛ«ΛΙΓΘΤ…Φ‘ΛœΛΣΛΫΛιΛ·Λ≥ΛΈΞαΞΫΞΟΞ…Λ§
ΛΛΛ≠Λ Λξ ―Ωτ carry ΛρΞΝΞßΞΟΞ·ΛΖΛΤΛΛΛκΛΈΛΥ
ΧΧΛ·ΛιΛΠΛΪΛβΛΖΛλΛόΛΜΛσΓΘΛ≥ΛλΛρΆΐ≤ρΛΙΛκΛΥΛœΓΔΛ≥ΛΈΞαΞΫΞΟΞ…ΛΈ
≥Α¬ΠΛΥΛΔΛκΞκΓΦΞΉ (ΗΪΛ®Λ ΛΛ) ΛρΝέΝϋΛΙΛκ…§ΆΉΛ§ΛΔΛκΛΈΛ«ΛΙΓΘ
def fg(args): if not args: yield "" return for i in args[0]: for tmp in fg(args[1:]): yield i + tmp return
Λ≥ΛλΛœΞΛΞΤΞλΓΦΞΩ»«ΛηΛξΛβ¥ Ο±Λ«ΛΔΛκΛάΛ±Λ«Λ Λ·ΓΔ ΚΤΒΔΛρΜ»ΛΟΛΩΞΣΞξΞΗΞ ΞκΛΈΞ–ΓΦΞΗΞγΞσΛηΛξΛβΛΒΛιΛΥ¥ Ο±ΛΥΛ ΛΟΛΤΛΛΛκΛ≥Λ»ΛΥ ΒΛΛ≈Λ≠ΛόΛΙΓΘΞΗΞßΞΆΞλΓΦΞΩΛρΜ»ΛΠΛ»ΓΔΖκ≤ΧΛρΑλ≤σΛΥΛ“Λ»ΛΡΛΚΛΡΛΩΛσΛΥ≈ξΛ≤ΛΤΛΛΛ· (ΛΔΛκΛΛΛœ "yield ΛΖΛΤΛΛΛ·") ΛάΛ±Λ«ΛηΛ·ΓΔ≈ξΛ≤ΛΩΛΔΛ»ΛœΥΚΛλΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙΓΘ Λ≥ΛλΛœΖκ≤ΧΛρΞΙΞ»ΞξΓΦΞύΫΖΞΛΞΙΛΥ…ΫΦ®ΛΙΛκΛΈΛΥΜςΛΤΛΛΛόΛΙΓΘ Ψθ¬÷Λρ ί¬ΗΛΙΛκΛηΛΠΒΛΛρΛΡΛΪΛΠ…§ΆΉΛœΛΔΛξΛόΛΜΛσΓΘ ΛΩΛάΛΙΛΌΛΤΛΈΖκ≤ΧΛρ≤ΩΛβΙΆΛ®ΛΚΛΥάΗά°ΛΖΓΔΛΫΛλΛ«ΛΛΛΤΛ ΛΣΛΪΛΡ Φξ¬≥Λ≠ΛΥ¬–ΛΖΛΤΗΖΧ©Λ Ξ≥ΞσΞ»ΞμΓΦΞκΛρΑίΜΐΛ«Λ≠ΛκΛΈΛ«ΛΙΓΘ ΜςΛΩΒΓ«ΫΛœΛΛΛ·ΛΡΛΪΛΈ¥ΊΩτΖΩΗάΗλΛ«ΞΒΞίΓΦΞ»ΛΒΛλΛΤΛΛΛκΓ÷ΟΌ±δ…Ψ≤Ν (lazy evaluation)ΓΉΛ«ΛβΦ¬ΗΫΛ«Λ≠ΛκΛ≥Λ»ΛΥΒΛΛ≈ΛΪΛλΛκΛΪΛβΛΖΛλΛόΛΜΛσΓΘ ΟΌ±δ…Ψ≤ΝΛ»ΞΗΞßΞΆΞλΓΦΞΩΛœΛόΛΟΛΩΛ·Τ±ΛΗΛβΛΈΛ«ΛœΛΔΛξΛόΛΜΛσΛ§ΓΔ Λ≥ΛλΛιΛœΛ…ΛΝΛιΛβΤ±ΛΗΨθΕΖΛρΛΌΛΡΛΌΛΡΛΈΛδΛξ ΐΛ«ΫηΆΐΛΙΛκΛΈΛΥΧρΈ©ΛΝΛόΛΙΓΘ
¥ΊΩτΖΩΞΉΞμΞΑΞιΞΏΞσΞΑΛΥ¥ΖΛλΛΤΛΛΛκΩΆΛ«ΛΔΛλΛ–ΓΔ ΞΣΞ÷ΞΗΞßΞ·Ξ»ΛηΛξΛβ lambda ΦΑΛΥΛηΛκΞΪΞΉΞΜΞκ≤ΫΛρΙΞΛύΛΪΛβΛΖΛλΛόΛΜΛσΓΘ Python Λ«ΛœΛ≥ΛλΛβ≤Ρ«ΫΛ«ΛΙΓΘΛΖΛΪΛΖΦ¬ΚίΛΥΛœΓΔΛ≥ΛλΛœΛΪΛ ΛξΛύΛΚΛΪΛΖΛΛΞ―ΞΚΞκΛ«ΛΖΛΩΓΘ ΞΛΞΤΞλΓΦΞΩΛ»Τ±ΛΗΛδΛξ ΐΛ«ΛβΛ«Λ≠ΛΩΛΈΛ«ΛΙΛ§ΓΔΛ≥Λ≥Λ«ΛœΛόΛΟΛΩΛ· ΧΛΈ ΐΥΓΛρ ΜνΛΖΛΤΛΏΛηΛΠΛ»ΜΉΛΟΛΩΛΈΛ«ΛΙΓΘΩτΜΰ¥÷ΛΥΛοΛΩΛκΜνΙ‘ΚχΗμΛΈΛΠΛ®ΓΔΚ«ΫΣ≈ΣΛΥ Λ«Λ≠ΛΩΛΈΛœΦΓΛΈΛηΛΠΛ ΛβΛΈΛ«ΛΖΛΩ:
def fl(args, i=0, tmp="", parent_sibling=None): if not args: # Ά’ΛΥΛΛΛκ return (tmp, parent_sibling) if i < len(args[0]): # ΈΌΛΈάα≈ά (ΖΜΡο, sibling) ΛρΫύ»ς sibling = fl(args, i+1, tmp, parent_sibling) return lambda: fl(args[1:], 0, tmp+args[0][i], sibling) else: # Λ“Λ»ΛΡΨεΛ§ΛΟΛΤΩΤΛΈΖΜΡοΛρΛΩΛΚΛΆΛκ return parent_sibling # lambda Ξ–ΓΦΞΗΞγΞσΛΈΟΒΚςΞκΓΦΞΝΞσ def traverse(n): while n: if callable(n): # άα≈ά n = n() else: # Ά’ (result, n) = n print result, print
¥πΥή≈ΣΛ ΞΔΞΛΞ«ΞΔΛœΓΔΛ≥ΛλΛρΥή≈ωΛΥΧΎΛΈΟΒΚςΛ»ΛΖΛΤΑΖΛΠΛ»ΛΛΛΠΛβΛΈΛ«ΛΙΓΘ
¥ΊΩτ f Λœ≥Τάα≈άΛΥ…τ §≈ΣΛ ≤ρΛρΛβΛΟΛΩΧΎΛ»ΛΖΛΤΛΏΛκΛ≥Λ»Λ§Λ«Λ≠ΛόΛΙ (Ωό 2)ΓΘ
fl Λ§ ÷ΛΙ¥ΊΩτΛœΛΫΛΈΑΧΟ÷Λ»ΈΌΛΈάα≈ά (sibling)ΓΔΛΣΛηΛ”
ΩΤΛΈάα≈άΛΈΈΌΛΈάα≈άΛρ ίΜΐΛΖΛΤΛΛΛόΛΙΓΘΛ≥ΛΈ¥ΊΩτΛ§ΧΎΛρ≤ΦΛΟΛΤΛΛΛ·ΛΥΛΡΛλΛΤ
ΞΌΞ·Ξ»ΞκΛΈΆΉΝ«Λ§Ρ…≤ΟΛΒΛλΛΤΛΛΛ≠ΛόΛΙΓΘΛ≥ΛλΛ§Ά’ΛΥΛΡΛΛΛΩΛ»Λ≠ΓΔ
ΛΫΛΈ¥ΊΩτΛœΛ“Λ»ΛΡΛΈ¥ΑΝ¥Λ ≤ρ (Ν»ΛΏΙγΛοΛΜ) ΛρΦξΛΥΛΖΛΤΛΛΛκΛœΛΚΛ«ΛΙΓΘ
Τ±ΛΗΙβΛΒΛΥΛβΛΠΛΫΛλΑ ΨεΟΒΚςΛΙΛΌΛ≠άα≈άΛ§Λ ΛΛΨλΙγΓΔ¥ΊΩτΛœΛ“Λ»ΛΡΨεΛΥΨεΛ§ΛΟΛΤ
ΩΤΛΈΈΌΛΊΛ»Ω ΛΏΛόΛΙΓΘΛ≥ΛΈΧΎΛρΟΒΚςΛΙΛκΛΥΛœΤΟ ΧΛΥΆ―Α’ΛΒΛλΛΩ
¥ΊΩτ (Ξ…ΞιΞΛΞ–) Λ§…§ΆΉΛΥΛ ΛξΛόΛΙΓΘ
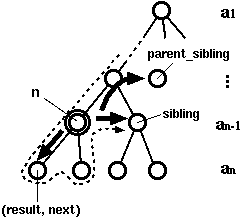
ΛβΛΝΛμΛσΓΔΞΗΞßΞΆΞλΓΦΞΩ»«Λ«ΛβΧΎΛΈΟΒΚςΛρΛΣΛ≥Λ ΛΠΛ≥Λ»ΛœΛ«Λ≠ΛόΛΙΓΘ ΛΫΛΈΨλΙγΓΔΧΎΛΈ≥Τάα≈άΛ«Ζκ≤ΧΛρ≈ξΛ≤ΛΤΛΛΛ·Λ»ΛΛΛΠΛ≥Λ»ΛΥΛ ΛκΛ«ΛΖΛγΛΠΓΘ